Health Screening¶
In this step-by-step walkthrough, you'll build a conversational health screening application that allows users to identify their risk of prediabetes.
Working through this blueprint will teach you how to
- configure a MindMeld application in a language different than English
- learn custom entities
- use dialogue flows to structure the conversation
Note
Please make sure to install and run all of the pre-requisites for MindMeld before continuing with this blueprint tutorial.
1. The Use Case¶
This screening application would be offered by a public health department through a messaging service like SMS or WhatsApp. Users should be able to provide answers to a series of questions asked in Spanish and receive an assessment about their risk for prediabetes. They should be able to opt-out of the questionnaire at any time. A user's risk is calculated based on the questionnaire provided by the American Diabetes Association and the Centers for Disease Control and Prevention.
2. Example Dialogue Interactions¶
The conversational flows for health screening will primarily involve asking users a series of questions about their medical history relevant to prediabetes. Once all necessary questions have been answered, the users are informed of their risk for presenting prediabetes.
Here is an example of a scripted dialogue interaction for conversational flows. Although the screening is done in Spanish, for instructional purposes, we demonstrate the same interaction in English.

3. Domain-Intent-Entity Hierarchy¶
Here is the NLP model hierarchy for our screening application.
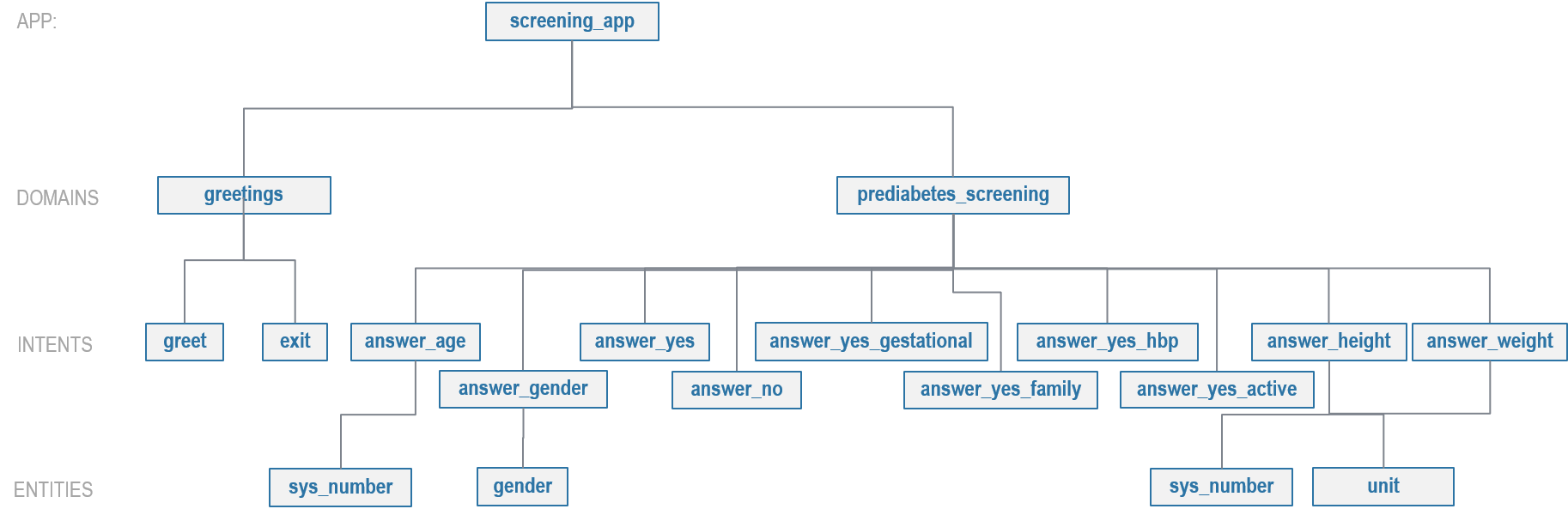
The screening blueprint is organized into two domains: greetings and prediabetes_screening.
The full list of intents for both domains is illustrated below.
The greetings domain supports the following intents:
greet— Greet the user and ask them if they would like to be screened for prediabetes.exit— Opt-out of the screening and say bye to the user.
The prediabetes_screening domain supports the following intents:
opt_in— User chooses to undergo the screening.answer_age— User wants to provide their age.answer_gender— User wants to provide their gender.answer_yes— User wants to answer a question with an explicit "yes".answer_no— User wants to answer a question with an explicit "no".answer_yes_gestational— User wants to answer the question regarding gestational diabetes with an implied "yes". For example, the answer: "During my first pregnancy" implies an affirmative response.answer_yes_family— User wants to answer the question regarding family history of diabetes with an implied "yes".answer_yes_hbp— User wants to answer the question regarding high blood pressure with an implied "yes".answer_yes_active— User wants to answer the question regarding physical activity with an implied "yes".answer_height— User wants to provide their height.answer_weight— User wants to provide their weight.
There are two types of entities in MindMeld: System Entities and Custom Entities. System entities are pre-defined in MindMeld. Examples include sys_temperature, sys_time, and sys_interval. Custom entities are defined by the developers of each application. Within each entity folder, the file gazetteer.txt contains a list of values for each custom entity. A gazetteer provides a very strong signal to the classification models; however, it does not need to be a comprehensive list of all possible values for the custom entity.
The screening blueprint defines and uses the following custom entities:
gender: detects the gender of a user. For example: "soy {hombre|gender}", "{mujer|gender}" are both ways to indicate gender in Spanish.unit: detects the unit of measurement. For example: "{60|sys_number} {kilos|unit}"
The screening blueprint uses one system entity: sys_number (number). Some examples for annotation with system entities: "{43|sys_number}" and "{2|sys_number} {mts|unit}".
Exercise
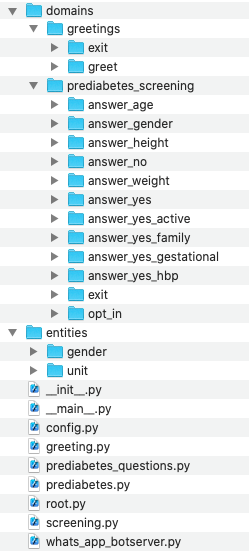
To train the different machine learning models in the NLP pipeline for this app, we need labeled training data that covers all our intents and entities. To download the data and code required to run this blueprint, run the command below in a directory of your choice.
python -c "import mindmeld as mm; mm.blueprint('screening_app');"
This should create a MindMeld project folder called screening_app in your current directory with the following structure:
4. Dialogue States¶
Dialogue state logic can be arbitrarily complex. Simple dialogue state handlers just return a canned text response, while sophisticated ones can call third party APIs, calculate state transitions, and return complex responses.
To support the functionality we envision, our app needs one dialogue state for each intent, as shown in the table below.
| Intent | Dialogue State Name | Dialogue State Function |
|---|---|---|
greet |
welcome |
Welcome the user and explain the system functions |
opt_in |
screen_prediabetes |
Begin a dialogue flow and ask the first screening question |
answer_age |
set_age_send_next |
Record the user's age and respond with the next question |
answer_gender |
set_gender_send_next |
Record the user's gender and respond with the next question |
answer_yes |
confirm_send_next |
If the user accepts the screening with an explicit "yes", the behavior is the same as opt_in.
If the answer is for a screening question, record True for that question and respond with the next question. |
answer_no |
negate_send_next |
If the user rejects the screening, exit the conversation. If the answer is for a screening question, record
False for that question and respond with the next question. |
answer_yes_gestational |
confirm_gestational_send_next |
Record True for having had gestational diabetes and respond with the next question. |
answer_yes_family |
confirm_family_send_next |
Record True for having a family history of diabetes and respond with the next question. |
answer_yes_hbp |
confirm_hbp_send_next |
Record True for having high blood pressure and respond with the next question. |
answer_yes_active |
confirm_active_send_next |
Record True for being physically active and respond with the next question. |
answer_height |
set_height_send_next |
Record the user's height and respond with the next question |
answer_weight |
set_weight_send_next |
Record the user's weight and respond with the user's risk for prediabetes |
exit |
say_goodbye |
End the current interaction |
Once a user has opted into the screening, a multi-turn dialogue begins where the goal is to answer all the screening questions. We can use dialogue flows to direct the user towards completing the screening. Here we illustrate how the dialogue states for the prediabetes_screening domain are defined using a dialogue flow.
@app.dialogue_flow(domain='prediabetes_screening', intent='opt_in')
def screen_prediabetes(request, responder):
...
@screen_prediabetes.handle(intent='answer_age')
def set_age_send_next(request, responder):
...
@screen_prediabetes.handle(intent='answer_gender')
def set_gender_send_next(request, responder):
...
@screen_prediabetes.handle(intent='answer_yes_gestational')
def confirm_gestational_send_next(request, responder):
...
@screen_prediabetes.handle(intent='answer_yes_family')
def confirm_family_send_next(request, responder):
...
@screen_prediabetes.handle(intent='answer_yes_hbp')
def confirm_hbp_send_next(request, responder):
...
@screen_prediabetes.handle(intent='answer_yes_active')
def confirm_active_send_next(request, responder):
...
@screen_prediabetes.handle(intent='answer_height')
def set_height_send_next(request, responder):
...
@screen_prediabetes.handle(intent='answer_weight')
def set_weight_send_next(request, responder):
...
@app.handle(intent='answer_yes')
@screen_prediabetes.handle(intent='answer_yes')
def confirm_send_next(request, responder):
...
@app.handle(intent='answer_no')
@screen_prediabetes.handle(intent='answer_no')
def negate_send_next(request, responder):
...
The @app.dialogue_flow decorator designates the flow's entry point. Once inside, every follow up turn will continue to be in this flow until we exit the flow. If the user response disrupts the flow by answering something unrelated to the prompt, we gently reprompt the user to provide a relevant answer. We can further control how the screening progresses by setting the allowed_intents attribute of the params object in the dialogue state handler. This attribute specifies a list of intents that you can set to force the language processor to choose from.
Observe that the dialogue states for confirm_send_next and negate_send_next have both the dialogue flow decorator and the normal decorator. These dialogue states handle explicit 'yes' and 'no' replies, respectively, that come both inside and outside the dialogue flow. For example, a user agreeing to the screening by saying ‘yes’ would be handled by the confirm_send_next dialogue state and would subsequently enter the dialogue flow. Similarly, a user answering ‘yes’ to a screening question would also be handled by this dialogue state.
5. Knowledge Base¶
The screening blueprint is a straightforward question-answer application. It has no catalogs and therefore does not need a knowledge base.
6. Training Data¶
The labeled data for training our NLP pipeline was created using a combination of in-house data generation and crowdsourcing techniques. This is a highly important multi-step process that is described in more detail in Step 6 of the Step-By-Step Guide. Be aware that at minimum, the following data generation tasks are required:
Purpose
|
Question (for crowdsourced data generators) or instruction (for annotators)
|
|---|---|
Exploratory data generation for guiding the app design
|
"How would you answer the questions in this questionnaire?"
|
Generate queries for training Domain and Intent Classifiers
|
answer_yes_active intent (prediabetes_screening domain):"Other than responding with an explicit "yes", how would you confirm that you are physically active?"
set_height_send_next intent (prediabetes_screening domain):"What would you say to the app to provide your height?"
|
Annotate queries for training the Entity Recognizer
|
set_weight_send_next: "Annotate all occurrences of sys_number and unit in the given query" |
Annotate queries for training the Role Classifier
|
The screening blueprint does not use roles.
For examples, please visit the home assistant blueprint.
|
Generate synonyms for gazetteer generation to improve entity recognition accuracies
|
unit entity: "Enumerate a list of abbreviations for the unit"gender entity: "What are different ways to indicate gender?" |
The domains directory contains the training data for intent classification and entity recognition. The entities directory contains the data for entity resolution. Both directories are at root level in the blueprint folder.
Exercise
- Read Step 6 of the Step-By-Step Guide for best practices around training data generation and annotation for conversational apps. Following those principles, create additional labeled data for all the intents in this blueprint and use them as held-out validation data for evaluating your app. You can read more about NLP model evaluation and error analysis in the user guide.
7. Training the NLP Classifiers¶
Setting up language configuration¶
MindMeld supports ISO 639-1 and ISO 639-2 language codes and ISO 3166-2 locale codes. Locale codes are represented as ISO 639-1 language code and ISO3166 alpha 2 country code separated by an underscore character, for example, en_US.
For the app to use Spanish in MindMeld, the config.py file needs to be configured as follows:
LANGUAGE_CONFIG = {
'language': 'es',
'locale': 'es_MX'
}
Note that Mexico (MX) is set as the locale as a demonstration, but in the case of Spanish, all locales are treated the same. If the language and locale codes are not configured in config.py, MindMeld uses this default:
LANGUAGE_CONFIG = {
'language': 'en',
'locale': 'en_US'
}
MindMeld supports most languages that can be tokenized like English. Apart from tokenization, there are two optional MindMeld components, stemming and system entities, that only support a subset of languages. Stemming and system entities are both supported for Spanish.
dc = nlp.domain_classifier
dc.view_extracted_features('yo tengo veinte años')
{
'bag_of_words_stemmed|length:1|ngram:anos': 1,
'bag_of_words_stemmed|length:1|ngram:teng': 1,
'bag_of_words_stemmed|length:1|ngram:veint': 1,
'bag_of_words_stemmed|length:1|ngram:yo': 1,
'bag_of_words_stemmed|length:2|ngram:teng veint': 1,
'bag_of_words_stemmed|length:2|ngram:veint anos': 1,
'bag_of_words_stemmed|length:2|ngram:yo teng': 1,
'bag_of_words|length:1|ngram:anos': 1,
'bag_of_words|length:1|ngram:tengo': 1,
'bag_of_words|length:1|ngram:veinte': 1,
'bag_of_words|length:1|ngram:yo': 1,
'bag_of_words|length:2|ngram:tengo veinte': 1,
'bag_of_words|length:2|ngram:veinte anos': 1,
'bag_of_words|length:2|ngram:yo tengo': 1,
'sys_candidate|type:sys_number': 1,
'sys_candidate|type:sys_number|granularity:None': 1
}
Training the NLP Classifiers¶
Train a baseline NLP system for the blueprint app. The build() method of the NaturalLanguageProcessor class, used as shown below, applies MindMeld's default machine learning settings.
from mindmeld.components.nlp import NaturalLanguageProcessor
import mindmeld as mm
mm.configure_logs()
nlp = NaturalLanguageProcessor(app_path='screening_app')
nlp.build()
Loading queries from file screening_app/domains/prediabetes_screening/answer_yes_active/train.txt
Loading queries from file screening_app/domains/prediabetes_screening/answer_yes_family/train.txt
Loading queries from file screening_app/domains/prediabetes_screening/answer_yes_gestational/train.txt
Loading queries from file screening_app/domains/prediabetes_screening/answer_yes_hbp/train.txt
Loading queries from file screening_app/domains/prediabetes_screening/exit/train.txt
Loading queries from file screening_app/domains/prediabetes_screening/opt_in/train.txt
Fitting domain classifier
Selecting hyperparameters using k-fold cross-validation with 10 splits
Best accuracy: 99.47%, params: {'C': 10, 'fit_intercept': True}
Fitting intent classifier: domain='greetings'
Selecting hyperparameters using k-fold cross-validation with 10 splits
Best accuracy: 97.77%, params: {'C': 0.01, 'class_weight': {0: 1.5061538461538462, 1: 0.7930817610062892}, 'fit_intercept': True}
Fitting entity recognizer: domain='greetings', intent='greet'
There are no labels in this label set, so we don't fit the model.
Fitting entity recognizer: domain='greetings', intent='exit'
There are no labels in this label set, so we don't fit the model.
Fitting intent classifier: domain='prediabetes_screening'
Selecting hyperparameters using k-fold cross-validation with 10 splits
Best accuracy: 98.37%, params: {'C': 1, 'class_weight': {0: 1.0488603988603988, 1: 1.0152380952380953, 2: 0.5086111111111111, 3: 1.1506472491909385, 4: 1.6275252525252526, 5: 1.1718076285240464, 6: 2.0179738562091503, 7: 0.7019113149847095, 8: 0.9538557213930349, 9: 3.804666666666667, 10: 1.6907407407407407, 11: 1.3684959349593495}, 'fit_intercept': True}
Fitting entity recognizer: domain='prediabetes_screening', intent='answer_gender'
Tip
During active development, it is helpful to increase the MindMeld logging level to better understand what is happening behind the scenes. All code snippets here assume that the logging level has been set to verbose.
To see how the trained NLP pipeline performs on a test query, use the process() method.
nlp.process('quiero conocer mi riesgo')
{
'text': 'yo mido 1 metro 57 cms',
'domain': 'prediabetes_screening',
'intent': 'answer_height',
'entities': [ {
'role': None,
'span': {'end': 8, 'start': 8},
'text': '1',
'type': 'sys_number',
'value': [{'value': 1}]
},
{
'role': None,
'span': {'end': 14, 'start': 10},
'text': 'metro',
'type': 'unit',
'value': [ {'cname': 'Metros',
'id': '38676',
'score': 1.7885764,
'top_synonym': 'Metros'
},
{'cname': 'Centimetros',
'id': '6744',
'score': 1.1168834,
'top_synonym': 'Centimetros'} ]
},
{
'role': None,
'span': {'end': 17, 'start': 16},
'text': '57',
'type': 'sys_number',
'value': [{'value': 57}]
} ],
}
For the data distributed with this blueprint, the baseline performance is already high. However, when extending the blueprint with your own custom data, you may find that the default settings may not be optimal and you could get better accuracy by individually optimizing each of the NLP components.
Start by inspecting the baseline configurations that the different classifiers use. The User Guide lists and describes the available configuration options. As an example, the code below shows how to access the model and feature extraction settings for the Intent Classifier.
ic = nlp.domains['prediabetes_screening'].intent_classifier
ic.config.model_settings['classifier_type']
'logreg'
ic.config.features
{
'bag-of-words': {'lengths': [1, 2]},
'enable-stemming': True
}
You can experiment with different learning algorithms (model types), features, hyperparameters, and cross-validation settings by passing the appropriate parameters to the classifier's fit() method. Here are a few examples.
Experiment with the intent classifiers¶
We can change the feature extraction settings to use bag of trigrams in addition to the default bag of words:
ic.config.features['bag-of-words']['lengths'].append(3)
ic.fit()
Fitting intent classifier: domain='prediabetes_screening'
Selecting hyperparameters using k-fold cross-validation with 10 splits
Best accuracy: 98.40%, params: {'C': 1, 'class_weight': {0: 1.0488603988603988, 1: 1.0152380952380953, 2: 0.5086111111111111, 3: 1.1506472491909385, 4: 1.6275252525252526, 5: 1.1718076285240464, 6: 2.0179738562091503, 7: 0.7019113149847095, 8: 0.9538557213930349, 9: 3.804666666666667, 10: 1.6907407407407407, 11: 1.3684959349593495}, 'fit_intercept': True}
Change the classification model to random forest instead of the default logistic regression:
ic.fit(model_settings={'classifier_type': 'rforest'}, param_selection={'type': 'k-fold', 'k': 10, 'grid': {'class_bias': [0.7, 0.3, 0]}})
Fitting intent classifier: domain='prediabetes_screening'
Selecting hyperparameters using k-fold cross-validation with 10 splits
Best accuracy: 96.90%, params: {'class_weight': {0: 1.0209401709401709, 1: 1.006530612244898, 2: 0.7894047619047618, 3: 1.0645631067961165, 4: 1.268939393939394, 5: 1.07363184079602, 6: 1.4362745098039216, 7: 0.8722477064220183, 8: 0.9802238805970149, 9: 2.202, 10: 1.2960317460317459, 11: 1.1579268292682925}}
You can use similar options to inspect and experiment with the Entity Recognizer and the other NLP classifiers. Finding the optimal machine learning settings is a highly iterative process involving several rounds of model training (with varying configurations), testing, and error analysis. See the User Guide for more about training, tuning, and evaluating the various MindMeld classifiers.
Exercise
Experiment with different models, features, and hyperparameter selection settings to see how they affect classifier performance. Maintain a held-out validation set to evaluate your trained NLP models and analyze misclassified instances. Then, use observations from the error analysis to inform your machine learning experimentation. See the User Guide for examples and discussion.
8. Parser Configuration¶
The relationships between entities in the screening queries are simple ones. For example, in the annotated query mido {2|sys_number} {metros|unit}?, the unit entity is self-sufficient, in that it is not described by any other entity.
If you extended the app to support queries with more complex entity relationships, it would be necessary to specify entity groups and configure the parser accordingly. For more about entity groups and parser configurations, see the Language Parser chapter of the User Guide.
Since we do not have entity groups in the screening app, we do not need a parser configuration.
9. Using the Question Answerer¶
The Question Answerer component in MindMeld is mainly used within dialogue state handlers for retrieving information from the knowledge base. Since the screening blueprint has no knowledge base, question answerer is not needed.
10. Testing and Deployment¶
Once all the individual pieces (NLP, Dialogue State Handlers) have been trained, configured or implemented, perform an end-to-end test of the app using the Conversation class.
from mindmeld.components.dialogue import Conversation
conv = Conversation(nlp=nlp, app_path='screening_app')
conv.say('quiero conocer mi riesgo')
['¿Cuál es su edad?', 'Listening...']
The say() method:
- packages the input text in a user request object
- passes the object to the MindMeld Application Manager to simulate an external user interaction with the app, and
- outputs the textual part of the response sent by the dialogue manager.
In the above example, we opted into the screening and the app responded with the first of the questions.
Try a multi-turn dialogue:
>>> conv = Conversation(nlp=nlp, app_path='screening_app')
>>> conv.say('Hola!')
['Bienvenido al sistema de evaluación de salud. Mediante unas sencillas preguntas, puedo ayudarte a determinar tu riesgo a padecer prediabetes. ¿Desea conocer su riesgo de padecer prediabetes?']
>>> conv.say("si")
['¿Cuál es su edad?', 'Listening...']
>>> conv.say("tengo 29 años")
['¿Es de género masculino o femenino?', 'Listening...']
>>> conv.say("soy mujer")
['¿Alguna vez ha sido diagnosticada con diabetes gestacional?', 'Listening...']
>>> conv.say("cuando tuve a mi primer hijo")
['¿Tiene algún familiar inmediato que haya sido diagnosticado con diabetes? Estos incluyen padre, madre, hermano o hermana.', 'Listening...']
Alternatively, enter conversation mode directly from the command-line.
python -m screening_app converse
You: Hola
App: Bienvenido al sistema de evaluación de salud. Mediante unas sencillas preguntas, puedo ayudarte a determinar tu riesgo a padecer prediabetes. ¿Desea conocer su riesgo de padecer prediabetes?
Exercise
Test the app and play around with different language patterns to discover edge cases that our classifiers are unable to handle. The more language patterns we can collect in our training data, the better our classifiers can handle in live usage with real users.
WhatsApp integration
Follow our tutorial on WhatsApp integration for more information on how to integrate with WhatsApp.